青年大学习截图是怎么回事呢?青年大学习相信大家都很熟悉,但是青年大学习截图是怎么回事呢,下面就让小编带大家一起了解吧。青年大学习截图,其实就是完成青年大学习所截的图片,大家可能会很惊讶青年大学习怎么会截图呢?但事实就是这样,小编也感到非常惊讶。这就是关于青年大学习截图的事情了,大家有什么想法呢,欢迎在评论区告诉小编一起讨论哦!
公众号:青春山东
注:签到功能只适用山东地区;如果只想获取截图(任意地区皆可),直接执行即可,无需修改openid。
环境:Python3
所需第三方库:requests(没有的pip install requests安装一下就好)
主要功能
- 一键完成所有大学习
- 完成任意一期大学习
- 获得截图(可能会失败、但成功可能性极高)
使用方法
- 修改第11行的openid为自己的,获取方法后文会提及。(如果不指定openid则只能获取截图。)将获取到的openid替换掉给出的1234567890AbCdEfGhIj_KlMnOpQ即可。(28个字符)
- python qndxx.py执行即可完成签到和截图。
- 如果想要执行一键签到所有将115行autosign()前“#”去掉即可。
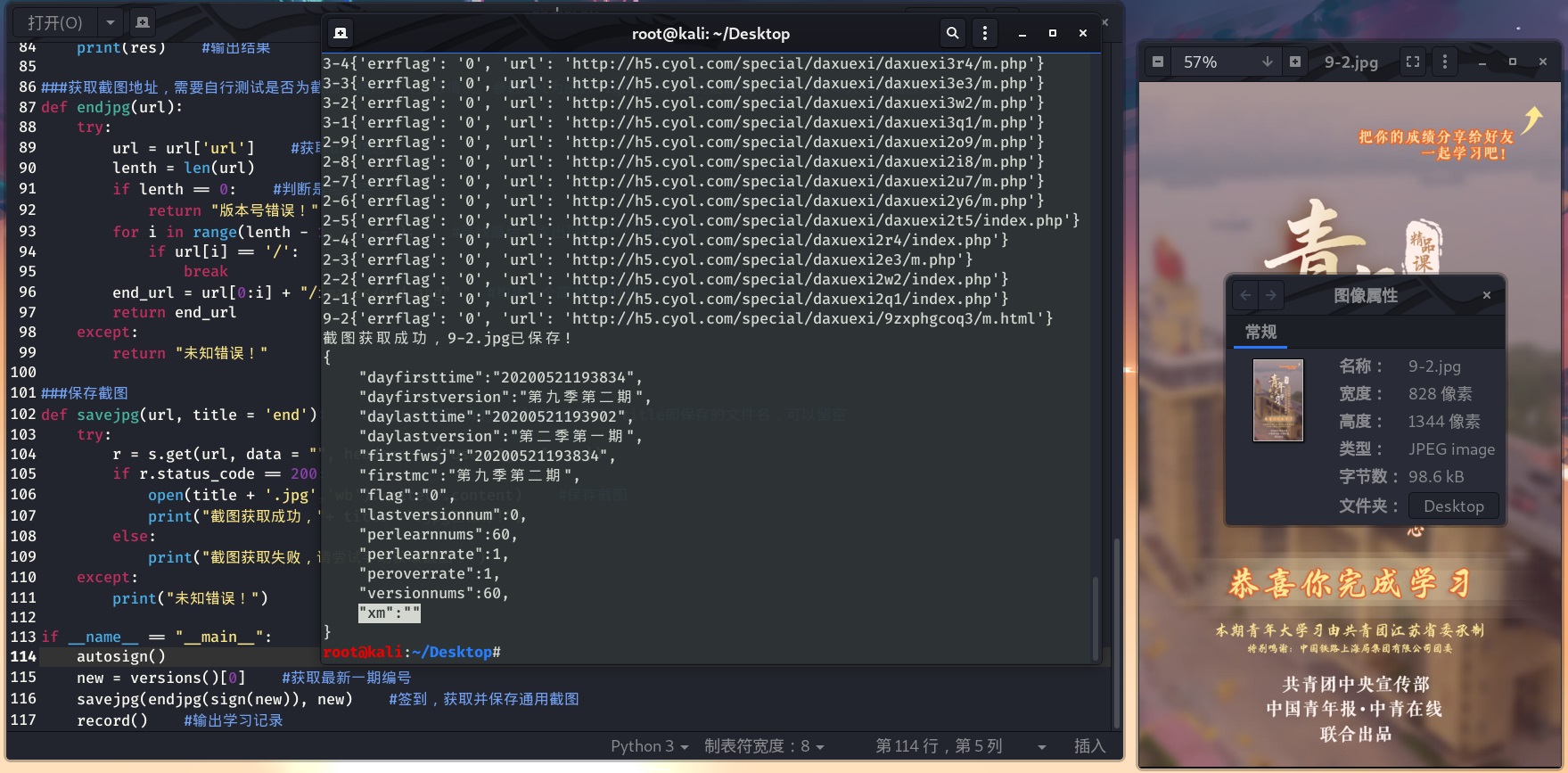
openid
什么是openid?
openid是微信用户在公众号appid下的唯一用户标识(appid不同,则获取到的openid就不同),可用于永久标记一个用户,同时也是微信JSAPI支付的必传参数。
如何获取?
- 抓包分析。这种方法略微麻烦就不说了。
- 访问特殊页面获取。
① 打开任意一期团课
② 进入我的学习日志
③ 复制链接得到的链接就包含了openid,即字符串中的”…openid=xxxxx&….”其中的xxxxx就是所需的openid。
复制到的链接大概这样http://qndxx.youth54.cn/SmartLA/lottery.w?method=openFxjm&openid=1234567890AbCdEfGhIj_KlMnOpQ
脚本(点我下载)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
###公众号青春山东,需要修改openid
import requests
import time
import re
import json
import os
global openid, ua, xm, sjhm, dw, tzb, zzbh
openid = "1234567890AbCdEfGhIj_KlMnOpQ" #微信openid,系统判别方式
ua = "Mozilla/5.0 (Linux; Android 9; QNDXX 666 Pro Build/PKQ1.180917.001; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/66.0.3359.126 MQQBrowser/6.2 TBS/045111 Mobile Safari/537.36 MMWEBID/3667 MicroMessenger/7.0.14.1660(0x27000E37) Process/tools NetType/4G Language/zh_CN ABI/arm64 WeChat/arm64" #模拟微信UA
root_url = "http://qndxx.youth54.cn" #根地址
#save_url = "/SmartLA/lottery.w?method=saveUser" #保存地址,即签到地址
record_url = "/SmartLA/lottery.w?method=openFxjm&openid=" + openid #学习记录地址
userinfo_url = "/SmartLA/lottery.w?method=enterUpdateUserInfo&openid=" + openid #用户信息获取地址
nvi_url = "/SmartLA/dxxjfgl.w?method=getNewestVersionInfo&openid=" + openid #获取最新大学习信息
sign_url = "/SmartLA/dxxjfgl.w?method=studyLatest" #签到地址
ubi_url = "/SmartLA/dxxjfgl.w?method=getUserBasicInfo&openid=" + openid #获取用户信息
s = requests.Session() #建立会话
###尝试获取用户信息,不检验openid是否合法
def getuserinfo():
try:
r = s.post(root_url + userinfo_url,data = "", headers = {"User-Agent": ua})
res1 = re.findall(": (.*?),",r.text) #筛选信息,正则表达式出现了点问题,无法正确匹配...
for i in range(0,len(res1)): #暴力匹配
if res1[i][1:-1] == openid:
break
xm = res1[i + 1][1:-1] #姓名
sjhm = res1[i + 2][1:-1] #手机号码
dw = res1[i + 3][1:-1] #地区
tzb = res1[i + 4][1:-1] #团组织
zzbh = res1[i + 5][1:-1] #组织编号,团组织对应的编号,每个团组织都不一样
return xm, sjhm, dw, tzb, zzbh
except:
print("获取失败!")
###获取最新大学习期数和地址
def versions():
r = s.post(root_url + nvi_url,data = "", headers = {"User-Agent": ua})
version = r.json()['version']
url = r.json()['url']
return version, url
##签到
def sign(version = '9-b'): #签到最新一期,书写方式例如"7-7"
headers = {
"User-Agent" : ua,
"X-Requested-With": "XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
data = {
"openid": openid,
"version":version
}
r = s.post(root_url + sign_url, data = data, headers = headers)
print(r.json())
return r.json()
##学习记录
def record():
r = s.get(root_url + record_url,data = "", headers = {"User-Agent": ua})
res = re.findall("var canshu=(.*?);",r.text)[0][1:-1] #筛选信息
res = json.dumps(json.loads(res), sort_keys=True, indent=4, separators=(',', ':')) #转成字典、文本化
res = eval(repr(res).replace('\\\\', '\\')) #将"\\"替换成"\",解决直接打印unicode
print(res) #输出结果
##获取用户信息
def getubi():
r = s.get(root_url + ubi_url,data = "", headers = {"User-Agent": ua})
res = json.dumps(r.json(), sort_keys=True, indent=4, separators=(',', ':')) #转成字典、文本化
res = eval(repr(res).replace('\\\\', '\\')) #将"\\"替换成"\",解决直接打印unicode
print(res) #输出结果
##获取截图地址,需要自行测试是否为截图,适用于大多数情况。url为sign()签到后的返回值。
def endjpg(url,v = 'end'):
try:
for i in range(len(url) - 1, -1, -1): #寻找最后一次出现字符'/'时的位置
if url[i] == '/':
break
end_url = url[0:i] + "/images/end.jpg" #构建一个简单截图链接
try:
r = s.get(end_url, data = "", headers = {"User-Agent": ua})
if r.status_code == 200:
open('./'+ v + '.jpg','wb').write(r.content)
print(v + '.jpg\t' + end_url)
else:
print("截图链接无效,请手动获取截图!")
except:
print("保存失败!")
return end_url
except:
return "未知错误!"
if __name__ == "__main__":
print(time.strftime("[%Y/%m/%d %H:%M:%S]\t"), end = '')
version, url = versions()
if version == '10-4-1':
print("截图"+ version +"需要手动获取!")
exit(0)
if os.path.exists('./'+ version + '.jpg'):
print("截图"+ version +".jpg已存在!")
exit(0)
sign(version)
endjpg(url,version) #获取最新一期截图地址
最后,还是希望大家能够抽出时间来认真大学习!
